 前 K 个高频元素
前 K 个高频元素
题目链接: https://leetcode.cn/problems/top-k-frequent-elements/
# LeetCode 347. 前 K 个高频元素
# 题目描述
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k高的元素。你可以按 任意顺序 返回答案。
举个例子:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
# 思路解析
# 方法一 hash表+桶排序
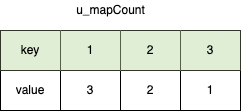
定义hash表u_mapCount统计数组nums中每个元素的频率,元素频率作为数组Freq的索引,对应频率元素组成的数组作为Freq的元素。
比如对于数组nums = [1,1,1,2,2,3]获取前k个高频元素步骤如下:
- 先统计其中元素的频率如下图。
- 然后使用桶排序,把元素频率作为数组
Freq的索引,对应频率元素组成的数组作为Freq的元素。
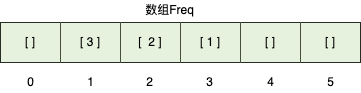
- 最后逆序获取二维数组
Freq中k个元素作为结果返回。
# C++代码
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
vector<int> res;
unordered_map<int, int> u_mapCount;
vector<vector<int>> Freq(nums.size() + 1, vector<int>());
//统计每个元素的频率
for (int i = 0; i < nums.size(); ++i) {
u_mapCount[nums[i]] += 1;
}
//元素的频率作为数组的索引,相同频率元素组成的数组作为数组的元素
for (auto& pair : u_mapCount) {
Freq[pair.second].emplace_back(pair.first);
}
//逆序获取k个最高频的元素
for (int i = Freq.size() - 1; i >= 0; --i) {
for (int j = 0; j < Freq[i].size(); ++j) {
res.emplace_back(Freq[i][j]);
if (res.size() == k) {
return res;
}
}
}
return res;
}
};
# 复杂度分析
时间复杂度: 构造hash表需要遍历一遍数组nums,然后构造频率表需要遍历一遍hash表,总的时间复杂度为O(n),其中n为数组nums的长度。
空间复杂度: 需要用到一个hash表和一个频率表,他们的长度均为n,所以空间复杂度为O(n)。
# 方法二 使用小根堆
本题也可以利用小根堆的特点来解,c++中可以使用优先队列(可以实现堆的操作)。
定义hash表u_mapCount统计数组nums中每个元素的频率,优先队列q用来存放频率最大的k个元素。
把hash表u_mapCount中的对象作为优先队列的元素,这里需要实现一个仿函数cmp作为优先队列模板类的参数,用作优先队列元素的排序。
class cmp {
public:
bool operator()(pair<int, int>left, pair<int, int> right) {
// 表示将u_mapCount中的对象根据频率排序,顺序为递减
// 用来实现小根堆
return left.second > right.second;
}
};
使用优先队列的算法如下:
- 使用
hash表u_mapCount统计数组nums中元素出现的频率。 - 遍历
hash表u_mapCount,如果优先队列q中元素个数小于k,将u_mapCount中的元素入队,否则,如果优先队列q中元素个数等于k且u_mapCount中元素大于q.top(), 就用u_mapCount中元素替换q.top()。 - 返回
nums在优先队列中存在的元素。
# C++代码
class cmp {
public:
bool operator()(pair<int, int>left, pair<int, int> right) {
// 表示将u_mapCount中的对象根据频率排序,顺序为递减
return left.second > right.second;
}
};
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
vector<int> res;
unordered_map<int, int> u_mapCount;
vector<vector<int>> Freq(nums.size() + 1, vector<int>());
for (int i = 0; i < nums.size(); ++i) {
u_mapCount[nums[i]] += 1;
}
//小根堆,堆中元素是pair类型的,pair为上面hash表u_mapCount中的一个对象
priority_queue<pair<int, int>, vector<pair<int, int>>, cmp> q;
for (auto& item : u_mapCount) {
if (q.size() < k) {
q.emplace(item);
} else {
//item的频率比小根堆中最小的值大,则替换它
//保持小根堆中不超过k个元素
if (q.top().second < item.second) {
q.pop();
q.emplace(item);
}
}
}
while(!q.empty()) {
res.emplace_back(q.top().first);
q.pop();
}
return res;
}
};
# 复杂度分析
时间复杂度: 构造hash表需要遍历一遍数组nums,优先队列插入的时间复杂度为O(logk),总的时间复杂度为O(nlogk),其中n为数组nums的长度,k为优先队列中元素的个数。
空间复杂度: 需要用到一个hash表和一个优先队列,他们的长度分别为n和k,其中k < n,所以空间复杂度为O(n)。
上次更新: 2024/07/08, 20:31:33