 字母异位词分组
字母异位词分组
题目链接: https://leetcode.cn/problems/group-anagrams/
视频题解: https://www.bilibili.com/video/BV1Fm42157HG/
# LeetCode 49. 字母异位词分组
# 题目描述
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
举个例子:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [ ["bat"], ["nat","tan"], ["ate","eat","tea"] ]
# 视频讲解
建议大家点击视频跳转到b站字母异位词分组 (opens new window)观看,体验更佳!
# 思路解析
本题的关键是找到字母异位词公共的特征,然后基于这个公共特征对所以的单词进行分类,这里介绍两种分类方法。
# 方法一 排序法
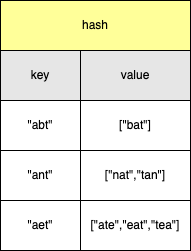
对每个单词拷贝一个副本,然后对单词的副本进行排序,排序后相等的单词存到同一个数组中。这里借用一个hash表,排序后的单词作为hash表的key。
对于strs = ["eat", "tea", "tan", "ate", "nat", "bat"],在hash表中的分布如下图:
# C++代码
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string, vector<string>> u_mapRes;
for (auto& str : strs) {
//对副本进行排序
string key(str);
sort(key.begin(), key.end());
//存到hash表中
u_mapRes[key].push_back(str);
}
for (auto& pair : u_mapRes) {
res.push_back(pair.second);
}
return res;
}
};
# java代码
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> res = new ArrayList<>();
Map<String, List<String>> u_mapRes = new HashMap<>();
for (String str : strs) {
//对副本进行排序
char[] charArray = str.toCharArray();
Arrays.sort(charArray);
String key = new String(charArray);
//存到哈希表中
if (!u_mapRes.containsKey(key)) {
u_mapRes.put(key, new ArrayList<>());
}
u_mapRes.get(key).add(str);
}
for (List<String> group : u_mapRes.values()) {
res.add(group);
}
return res;
}
}
# python代码
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
res = []
u_mapRes = defaultdict(list)
for str in strs:
#对副本进行排序
key = ''.join(sorted(str))
#存到哈希表中
u_mapRes[key].append(str)
for group in u_mapRes.values():
res.append(group)
return res
# 复杂度分析
时间复杂度: 排序需要O(nlogn),遍历数组需要O(n),所以整体的时间复杂度为O(nlogn),其中n是数组的长度。
空间复杂度: 需要借用一个hash表,最坏情况有n个key,所以空间复杂度为O(n),其中n是数组的长度。
# 方法二 字母统计法
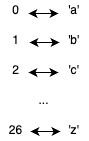
方法一中对单词进行排序需要 O(nlogn) 的时间复杂度,这里我们可以通过对单词中的字母进行统计替代排序来优化。因为单词只包含小写字母,字母总共26个,可以采用一个由数字组成,长为26的字符串来统计每个单词中的字母数量,然后将这个字符串作为方法一中hash表的key。
可以通过任意小写字母字的assci码减去小写字母a的assci码,得到任意小写字母在字符串中的位置,字符串的索引和小写字母位置的对应关系如下图:
思考:能否使用哈希表或数组作为哈希表的
key?需要做哪些额外操作?
# C++代码
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string, vector<string>> u_mapRes;
for (auto& str : strs) {
string count(26, '0');
for (auto& c : str) {
count[c - 'a'] += 1;
}
u_mapRes[count].push_back(str);
}
for (auto& pair : u_mapRes) {
res.push_back(pair.second);
}
return res;
}
};
# java代码
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> res = new ArrayList<>();
Map<String, List<String>> u_mapRes = new HashMap<>();
for (String str : strs) {
int[] count = new int[26];
for (char c : str.toCharArray()) {
count[c - 'a']++;
}
String key = Arrays.toString(count);
if (!u_mapRes.containsKey(key)) {
u_mapRes.put(key, new ArrayList<>());
}
u_mapRes.get(key).add(str);
}
for (List<String> group : u_mapRes.values()) {
res.add(group);
}
return res;
}
}
# python代码
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
res = []
u_mapRes = defaultdict(list)
for str in strs:
count = [0] * 26
for c in str:
count[ord(c) - ord('a')] += 1
u_mapRes[tuple(count)].append(str)
for group in u_mapRes.values():
res.append(group)
return res
# 复杂度分析
时间复杂度: 只需要遍历一遍数组统计字符,所以时间复杂度为O(n),其中n是数组的长度。
空间复杂度: 需要借用一个hash表,最坏情况有n个key,所以空间复杂度为O(n),其中n是数组的长度。